Сделали за 6 часов парсер сайтов по кастомным параметрам и сэкономили 150 часов джуна из команды SEO
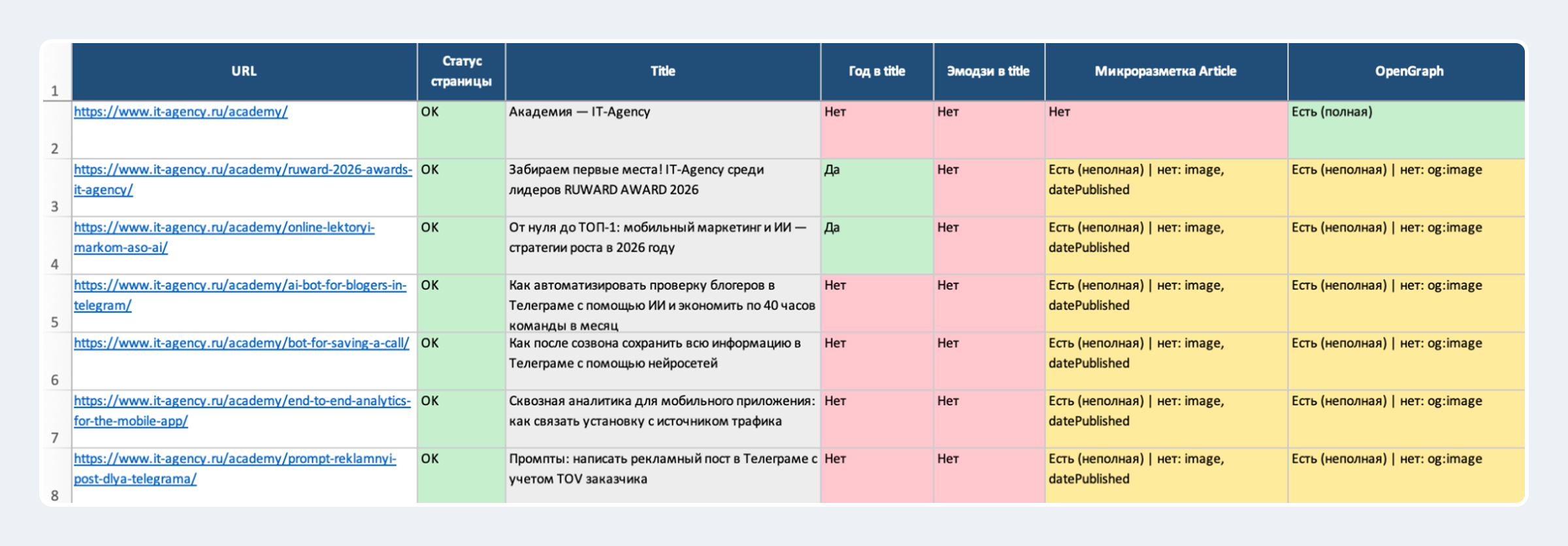
Целый класс задач в SEO выглядит просто, но убивает время: взять список из сотен страниц и по каждой проверить десяток параметров? Есть ли заголовок с актуальным годом? Добавлена ли микроразметка Article? Встроен ли FAQ-блок?
Моя коллега, Настя Муратова, принесла именно такую задачу — блог «Литрес Авторы», около 500 статей, 10+ параметров на каждую.
Оптимистичный сценарий: 20 минут на страницу, итого 160+ часов — полтора месяца работы джуна. С человеческими ошибками, выгоранием в конце и нулевым удовольствием от процесса.
«Мне нужен джун, подключу на задачу», — сказала Настя. Я предложил другое, о чём сейчас и расскажу.

Александр Рубцов
аккаунт-директор
В начале
В агентстве есть Свободные Четверги: специалист берёт один рабочий день и решает больной вопрос — чинит, что поломалось, автоматизирует то, что назрело.
От агентства — 8 часов без клиентских проектов, от себя — идея и менеджмент. В качестве разработчика выделяют неутомимого и продуктивного middle-специалиста на все руки — Claude Cowork. Или другой ИИ-инструмент на ваше усмотрение.
Задача идеально поддавалась алгоритмизации. Решено: трачу Свободный Четверг и ныряю в вайбкодинг.
Были ли другие решения?
Первое, что приходит в голову — популярные SEO-комбайны. Например, Screaming Frog или Labrika умеют многое: проверяют дубли тегов, переспам, технические ошибки, закрытые от индексации страницы.
Но у обоих одна и та же проблема — они работают с тем, что можно формализовать заранее.
Наши параметры формализовать стандартными средствами не получится.
- актуальный год в заголовке — не просто наличие цифры в Title, это логика: какой год сейчас и совпадает ли он с тем, что написано в контенте;
- наличие FAQ-блока — это не тег, а паттерн в контенте, который нужно распознать.
Ни Screaming Frog, ни Labrika, ни любой другой готовый сервис этого не умеют.
Специалист всё равно будет делать часть работы вручную, например, сводить данные из разных источников в одну таблицу — в итоге минус неделя. К тому же, Screaming Frog просит 250 евро в год, а Labrika — платную подписку, а бесплатные решения слишком слабые.
Нужно было кастомное решение, заточенное именно под наши параметры.
Процесс разработки
Основной инструмент — Claude Cowork и подписка за $20. Никаких других AI-инструментов я не использовал. Из технического: Python для логики парсера, инструмент для работы с браузером, библиотека для генерации Excel. Код хранится на GitHub, развёрнут на VPS-сервере.
Большинство подкопотных терминов и библиотек, которые использовал Claude я увидел впервые. Приятно, что Claude объяснял, как он будет решать ту или иную задачу, и аргументировал свой выбор. Пару раз я с ним спорил — просто чтобы убедиться, что он предлагает действительно лучшее решение.
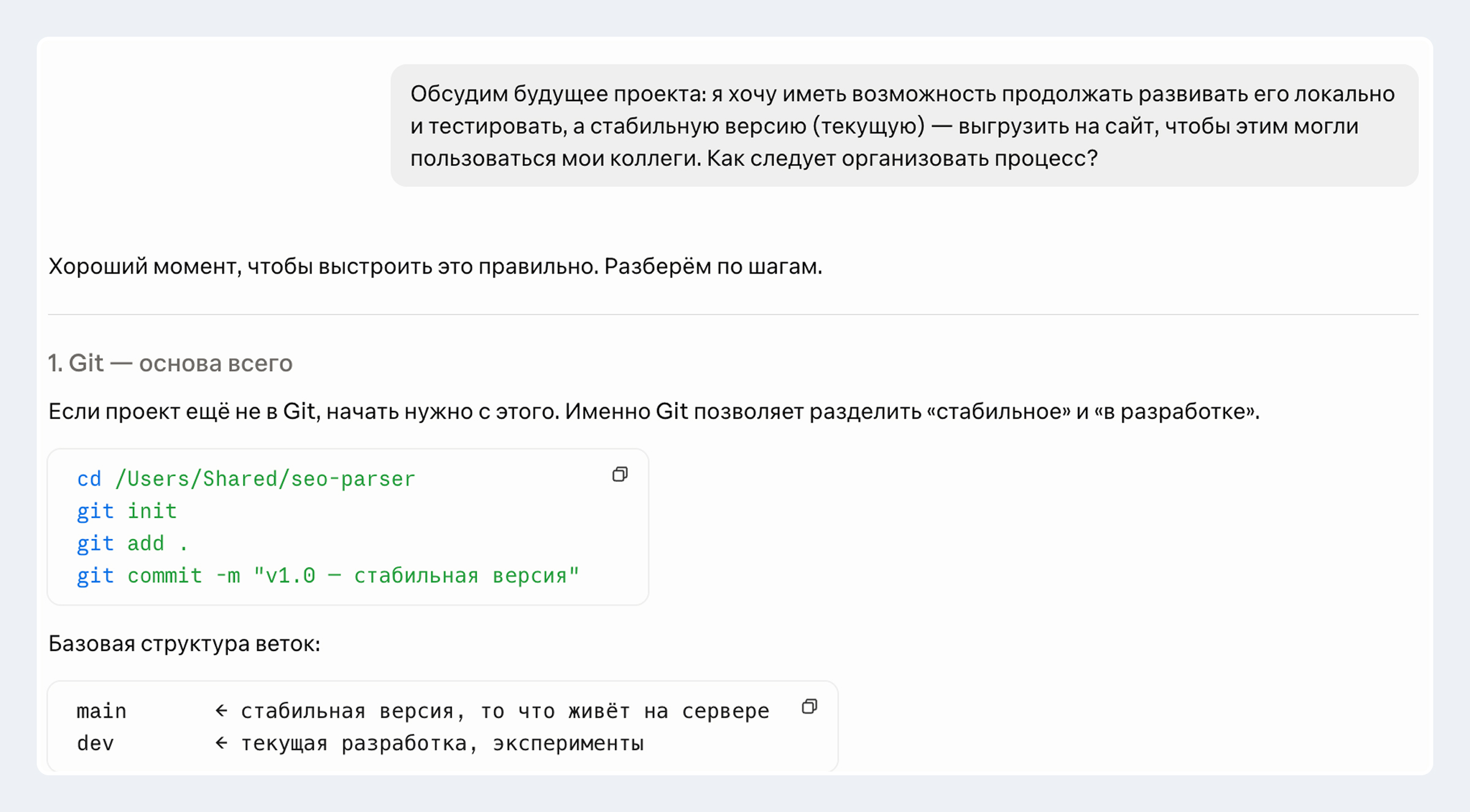
Здесь ИИ забыл, что по-хорошему сначала надо все тестировать в ветке DEV, и только потом стабильную версию раскатывать в MAIN.
Мучительно больно начинать с чистого листа, и главная ошибка — сразу закопаться в детали. Поэтому правильно двигаться от общего к частному.
На первой сессии я объяснил, что хочу: веб-приложение, куда можно вставить список URL, нажать кнопку и получить Excel с результатами по каждому параметру.
Мы начали с базовой архитектуры. Первую рабочую версию я увидел уже через несколько часов работы.

Дальше шли итерации: я тестировал инструмент на реальных страницах, находил то, что работает не так и описывал проблему. Claude правил код и объяснял, что именно было не так и почему. Так мы отлавливали баги и моменты, которые не учли в ТЗ изначально, шаг за шагом.
Отдельным этапом стало развёртывание сервиса на сервер. Я впервые в жизни настраивал VPS, он же виртуальный выделенный сервер. Claude провёл меня через каждый шаг — я просто вводил команды и скидывал результат, если что-то шло не так.
Интересные моменты и трудности
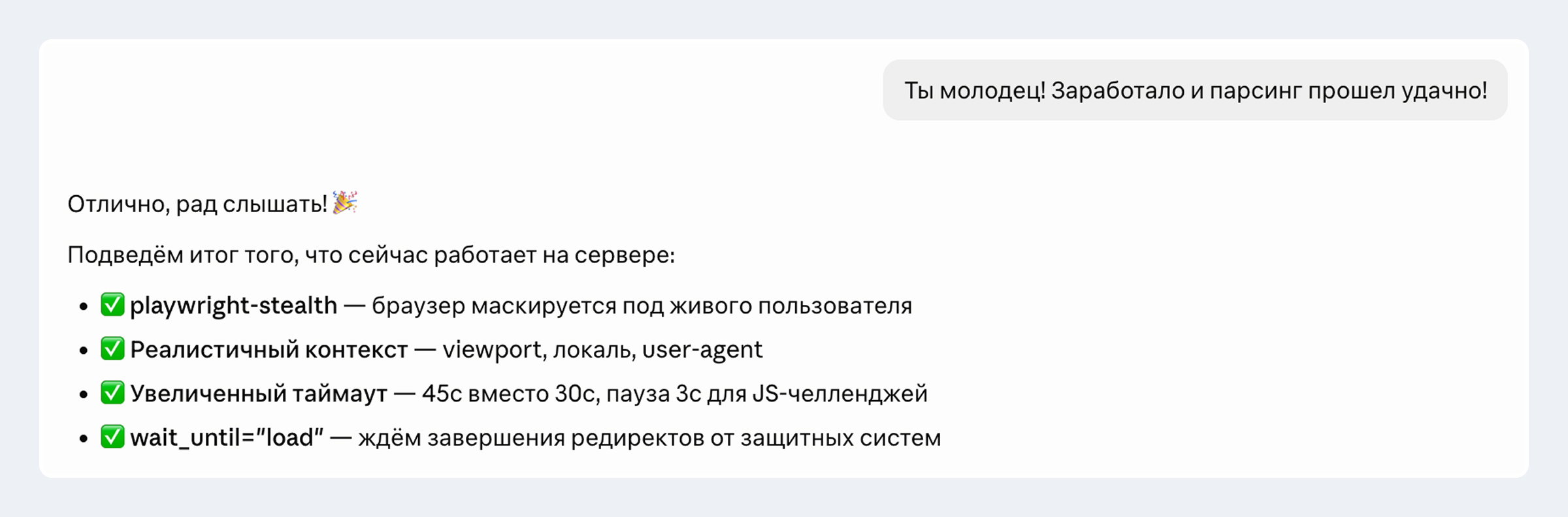
1. Научили парсер обходить защищённые сайты
Многие сайты — особенно крупные — используют системы защиты от автоматических запросов. Они отличают живого пользователя от программы и при подозрении блокируют запрос. Для парсера это выглядит как таймаут или пустая страница вместо контента.
Мы шли от простого к сложному. Сначала добавили базовые признаки live-запроса — правильные заголовки браузера и логику повторной попытки. Это помогло, но не во всех случаях. Тогда подключили инструмент, который скрывает характерные следы автоматизации от антибот-систем. После этого большинство защищённых сайтов стало парсится стабильно.

Искали решение.
И нашли.
2. Как мы добавляли JS-парсинг — и почему это потребовало нескольких итераций
Часть сайтов рендерит контент через JavaScript: браузер получает почти пустой HTML и «достраивает» страницу уже у себя. Обычный запрос такую страницу не видит вообще.
Мы добавили переключатель JS-режим и подключили инструмент, который управляет настоящим браузером в фоновом режиме. Теперь парсер буквально открывает страницу в Chrome, ждёт её загрузки и только потом считывает результат.

А в целом всё, потребовался один Свободный Четверг.
Как работает инструмент
1. Забрасываем URL.
Вставляем список страниц — номинально до 500 штук, чтобы сервер не завис на несколько часов, но глобально ограничений нет.
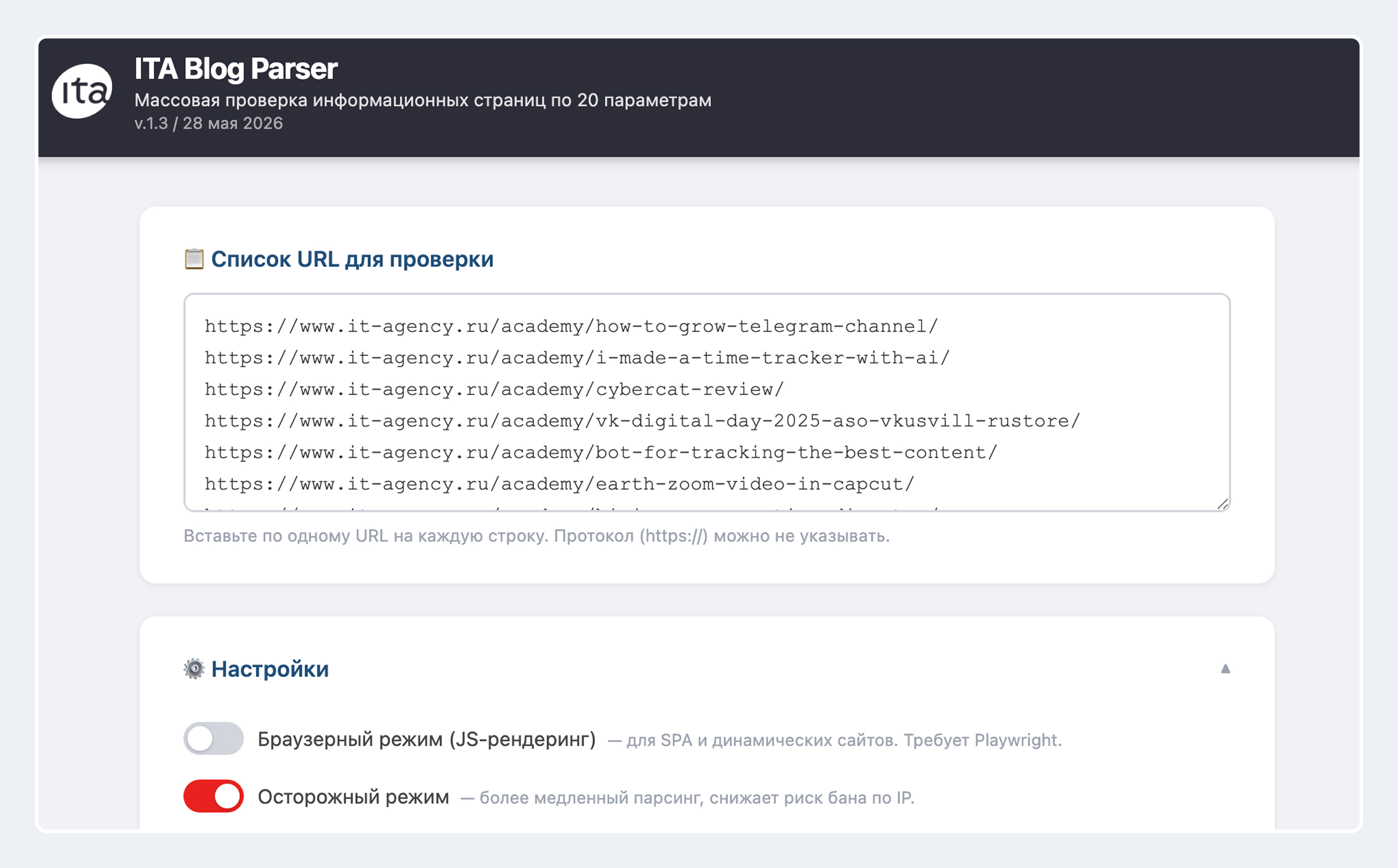
2. Выставляем настройки.
Если сайт рендерит контент через JavaScript — включаем JS-режим. Если сайт использует продвинутую защиту — включаем соответствующий режим. Можно также указать конкретную зону HTML-документа для анализа, чтобы исключить ложные срабатывания на элементах в шапке и подвале.
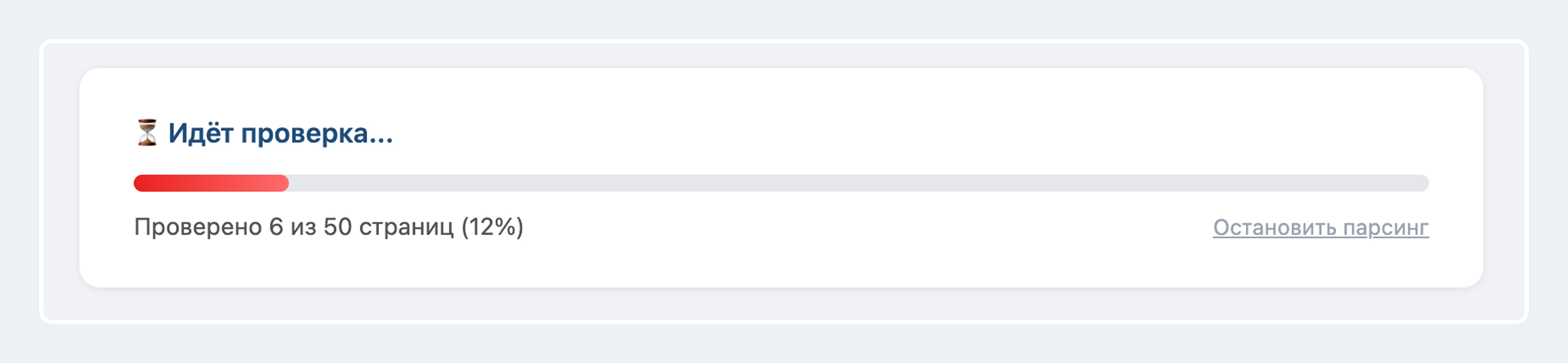
3. Запускаем, ожидаем.
100 URL без защиты парсит примерно за 4 минуты.
4. Скачиваем Excel.
Результаты парсинга забираем в привычном формате таблицы и работаем: фильтруем, сортируем, ставим нужные комменты.
Ключевой личный инсайт
Я выступил как product owner, а не как технический специалист — не ставил задачи в терминах кода, а описывал проблему и желаемый результат.
Заметил закономерность: чем больше контекста даёшь, тем лучше результат. Не «добавь проверку микроразметки», а «нам важно, чтобы разметка была валидна по правилам Google — вот почему». ИИ в таких случаях либо понимал задачу шире, либо предлагал более аккуратное решение.
Это, пожалуй, главный вывод: вайбкодинг работает не потому что ИИ умный, а потому что ты наконец-то думаешь о задаче как продукт-менеджер, а не как исполнитель.
Итоги
От момента «питча» на команду до MVP, запускаемого локально, — 6 часов. Ещё 3–4 часа ушло в другие дни: фикс мелких багов и развёртывание на сервер, чтобы специалист мог запускать сервис быстро и без проблем.
Итого 10 часов, а сколько пользы:
- Сэкономили до 150 часов специалиста-джуна, которому не надо вручную собирать огромную таблицу с проверенными параметрами.
- Исключили человеческий фактор: машина бездушно проверяет URL за URL, без перекура и ошибок.
- Сразу после релиза решение использовали ещё на трёх других проектах — сэкономив ещё вагон и тележку часов.
- Сделали парсер, который легко кастомизируется под новые проекты. Нужна проверка эмоджи? Да. Нужно найти все старые упоминания сайта до ребрендинга? Разрешите бегом!
Что дальше? Продолжаю допиливать инструмент под запросы команды.
Записал Александр Рубцов, отредактировал Сергей Афонин

Автоматизация
Эффективность
SEO
Инструменты
Подобрали для вас
Эффективность
 Свободные Четверги: как мы убрали из лексикона слово «не́когда» и создали сообщество энтузиастов в ИИ
Свободные Четверги: как мы убрали из лексикона слово «не́когда» и создали сообщество энтузиастов в ИИЭффективность
 Реклама бесплатных товаров в Яндекс Директ: как создать товарный фид без разработки с помощью ИИ
Реклама бесплатных товаров в Яндекс Директ: как создать товарный фид без разработки с помощью ИИЭффективность
 Промпты: оценка аудитории Телеграм-канала для рекламного размещения
Промпты: оценка аудитории Телеграм-канала для рекламного размещенияЕщё по теме «автоматизация»
Автоматизация
 Как автоматизировать проверку блогеров в Телеграме с помощью ИИ и экономить по 40 часов команды в месяц
Как автоматизировать проверку блогеров в Телеграме с помощью ИИ и экономить по 40 часов команды в месяцАвтоматизация
 Как редакторы с помощью ИИ собрали бота для отслеживания лучшего контента про маркетинг
Как редакторы с помощью ИИ собрали бота для отслеживания лучшего контента про маркетингАвтоматизация
 ChatGPT как личный ассистент: реальные примеры делегирования задач нейросети
ChatGPT как личный ассистент: реальные примеры делегирования задач нейросетиСтатьи из Академии
два раза в месяц
Даю согласие на обработку моих данных в соответствии с политикой обработки


Обсудим задачу
Мы свяжемся с вами в течение двух часов, чтобы задать вопросы и обсудить, какую пользу можем принести

Александр Кульгинский
управляющий партнёр