Кластеризатор ключевых слов на Excel Роман Игошин
Вручную группировать запросы не всегда эффективно: перебрать 200–300 запросов можно за час, на 20–30 тысяч уйдет неделя. Автоматическим сервисам группировку я не доверю, так как она определяет структуру и управляемость кампании.
Поэтому придумал свой метод, который ускоряет кластеризацию и даёт осознанный результат. Облегчает жизнь при работе с СЯ от 2–3 тысяч ключевых слов. Пробовал работать с 45 000 — Excel начинал умирать. Список из 200–300 запросов быстрее перебрать руками.
Далее расскажу про свой метод кластеризации в теории, а затем — как реализую его в Excel. Дам ссылку на готовый Excel-кластеризатор. Но чтобы им пользоваться, нужно хорошо понимать метод.

Роман Игошин
коммерческий директор, управляющий партнёр
Метод
Кластеризация — распределение запросов по кластерам. Кластер — это группа запросов, схожих по смыслу и набору слов. Чтобы выделить такие запросы и объединить их в кластер, нужен признак.
Используем для этого нормализованную форму запроса — уберём окончания и выстроим слова в порядке важности:
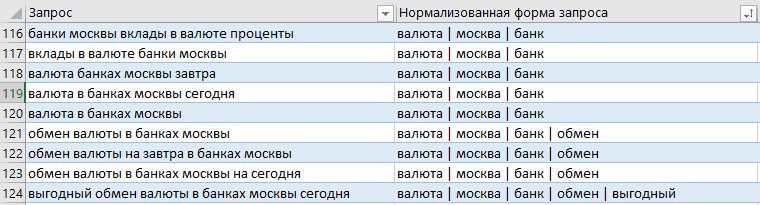
Пример готовых кластеров
Удаление окончаний позволит охватить все возможные словоформы для конкретного слова, а сортировка «по важности» — игнорировать порядок слов
Убираем окончания
Слово без окончания — это признак, который объединяет разные словоформы:
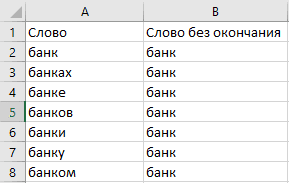
Объединение словоформ
Чтобы убирать окончания я использую mystem. Это лемматизатор от Яндекса. Он обрабатывает список слов и возвращает нормализованные значения — леммы.
Если система не уверена, какая лемма правильная, то покажет 2–3 варианта. Например, для слова «банку» mystem вернёт две леммы: «банк» и «банка». При проверке результатов мы выберем нужную.
Определяем важность
Сортировка «по важности» позволит игнорировать порядок слов. При сортировке нормализованных значений фраз по алфавиту мы получим готовые кластеры — группы запросов, схожих по смыслу и набору слов.
Важность слова — вычисляемый параметр для конкретного списка ключевых слов. Он не определяет важность слова в общей картине мира.
Важность слова рассчитывается из частотности и количества упоминаний слов в списке. Рассмотрим на примере.
Берём список запросов с частотностью
- Купить бумеранг: 1000
- Бумеранги цена: 700
- Бумеранги в москве: 750
- Купить классический бумеранг: 450
- Цены на бумеранги в москве: 350
- Купить классический бумеранг в москве: 100
В списке запросов встречаются слова: купить, бумеранг, классический, москва, цена, в, на. Вес слова равен сумме долей частотностей помноженных на количество упоминаний слова.
Считаем доли частотностей
- Купить бумеранг: 1000 = 1000/2 = 500
- Бумеранги цена: 700 = 700/2 = 350
- Бумеранги в москве: 750 = 750/3 = 250
- Купить классический бумеранг: 450 = 450/3 = 150
- Цены на бумеранги в москве: 350 = 350/5 = 70
- Купить классический бумеранг в москве: 100 = 100/5 = 20
Считаем вес слов
- Купить: (500+150+20)*3 = 2010
- Бумеранг: (500+350+250+150+70+20)*6 = 8040
- Классический: (150+20)*2 = 340
- Москва: (250+70)*2 = 640
- Цена: (350+70)*2 = 840
- В: 20
- На: 70
Сортируем по важности
- 8040: бумеранг
- 2010: купить
- 840: цена
- 640: москва
- 340: классический
- 70: на
- 20: в
Располагаем запросы по важности
- Купить бумеранг: бумеранг | купить
- Бумеранги цена: бумеранг | цена
- Бумеранги в москве: бумеранг | москва
- Купить классический бумеранг: бумеранг | купить | классический
- Цены на бумеранги в москве: бумеранг | цена | москва | на | в
- Купить классический бумеранг в москве: бумеранг | купить | москва | классический | в
Упорядочиваем и чистим
- Бумеранг | купить: купить бумеранг: 1000
- Бумеранг | купить | классический: купить классический бумеранг: 450
- Бумеранг | купить | москва | классический: купить классический бумеранг в москве: 100
- Бумеранг | москва: бумеранги в москве: 750
- Бумеранг | цена: бумеранги цена: 700
- Бумеранг | цена | москва: цены на бумеранги в москве: 350
В итоге получили первые группы объявлений, с которыми можно работать дальше: укрупнять, объединять, кросс-минусовать. Для этого используем Excel.
Реализация в Excel
Выполняем последовательность действий в таблице с формулами. Кластеризация 1000 запросов займет 30 минут.
Алгоритм одной строкой
Собираем СЯ → собираем частотность → разбиваем запросы по словам и вычисляем доли весов → формируем таблицу-справочник с весами слов → выделяем леммы для слов → вычисляем «вес» леммы → формируем таблицу-справочник с леммами → делаем первичную кластеризацию → укрупняем полученные группы.Шаг 1. Вычисляем доли весов и разбиваем запросы по словам
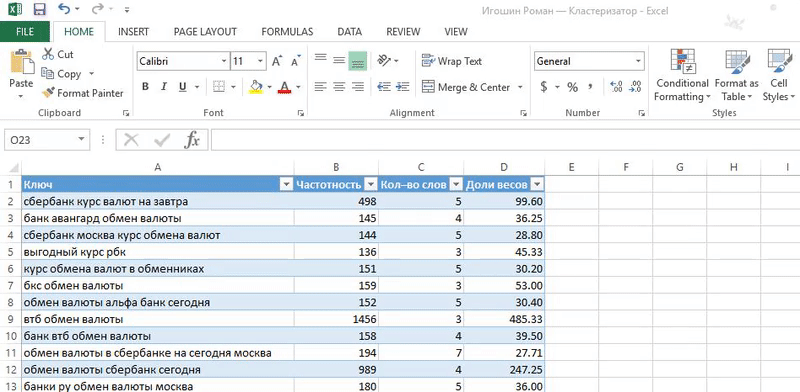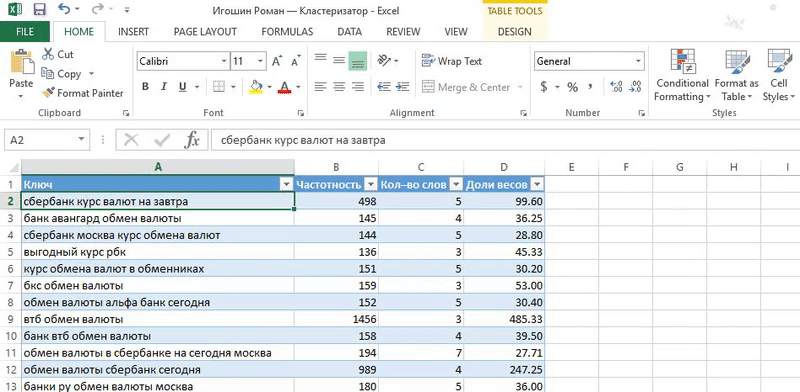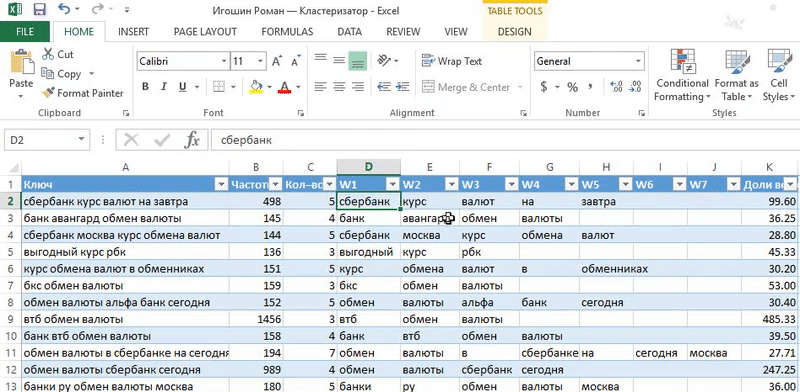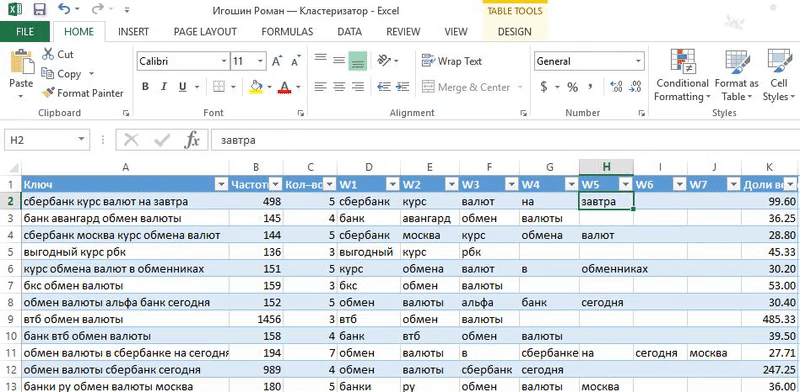
Шаг 1. Вычисляем доли весов и разбиваем запросы по словам
Лист «Кластеризация», таблица «Main»
1. Вычисляем доли весов:
Доли весов = Частотность / Кол-во слов.
Кол-во слов = LEN ([@Ключ])-LEN (SUBSTITUTE ([@Ключ]," ",""))+1.
Чтобы избежать правки формул называйте все листы и таблицы аналогично таблице-примеру
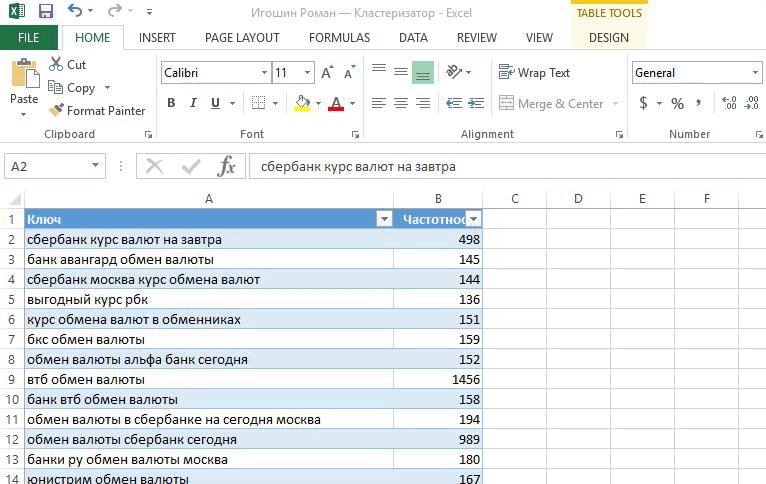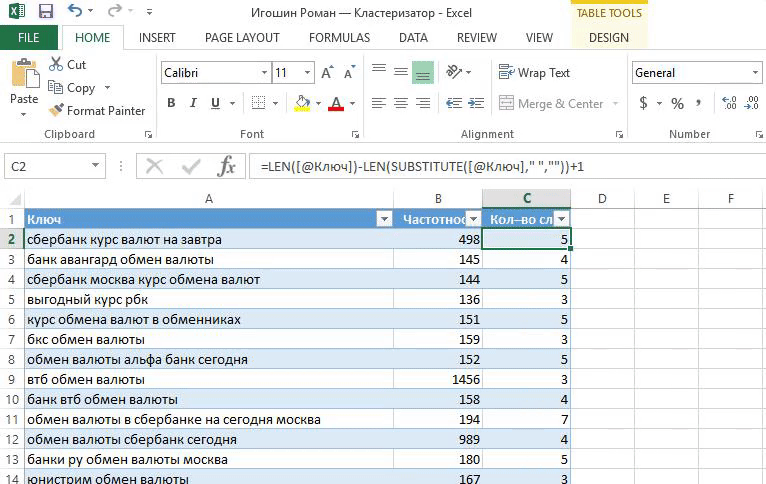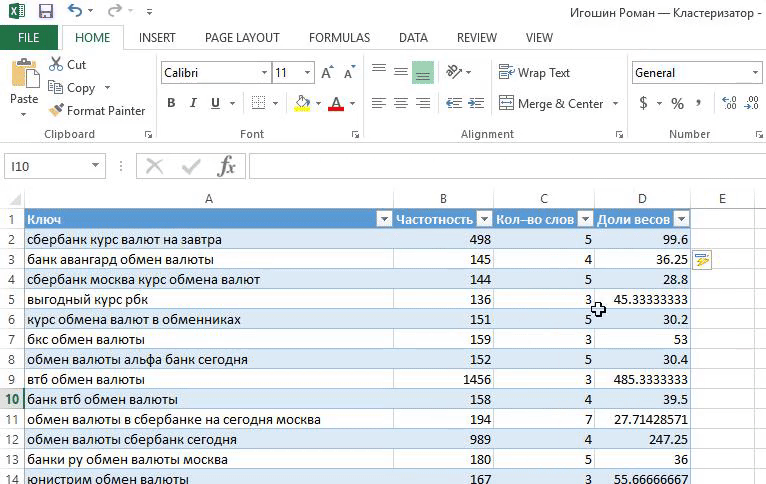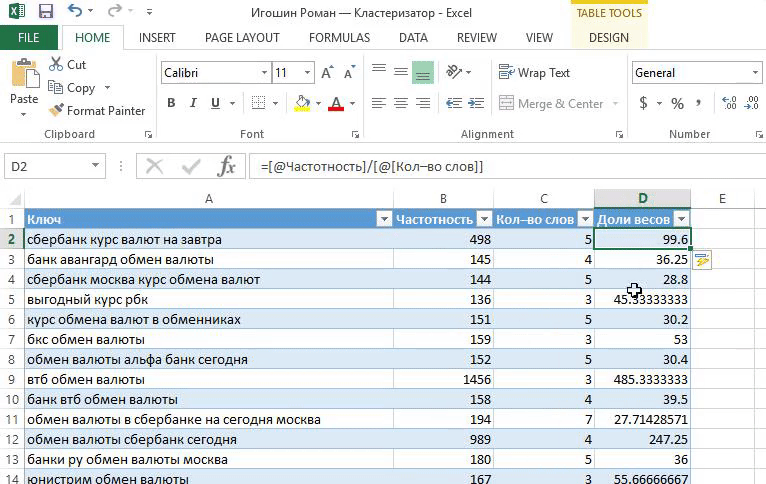
2. Разбиваем слова по фразам функцией «Text to columns»:
Шаг 2. Формируем таблицу-справочник с весами слов
Лист «Слова — Леммы», таблица «Word»
- Копируем столбцы W1—W7 на новый лист.
- Преобразуем таблицу из формата[W1] [W2] [W3] [W4] [W5] [W6] [W7] [Доли весов] в формат:[W1] → [Доли весов][W2] → [Доли весов][W3] → [Доли весов][W4] → [Доли весов][W5] → [Доли весов][W6] → [Доли весов][W7] → [Доли весов]:
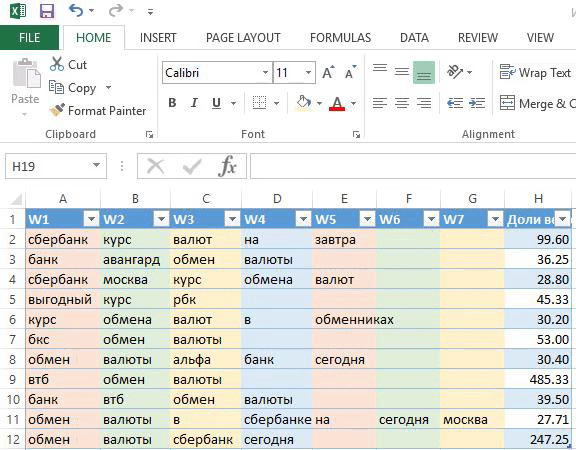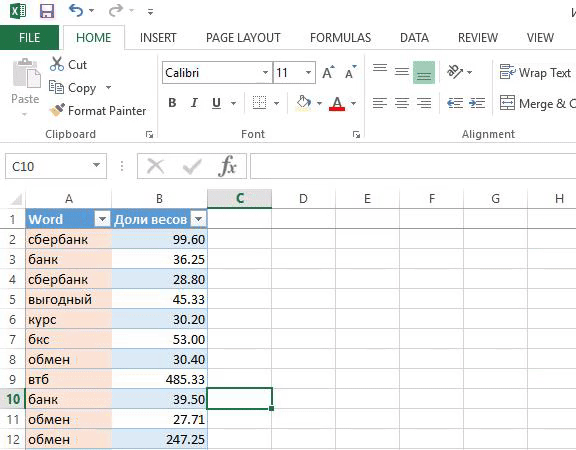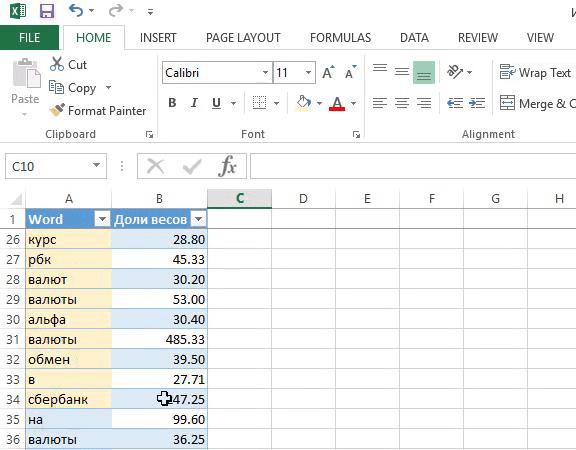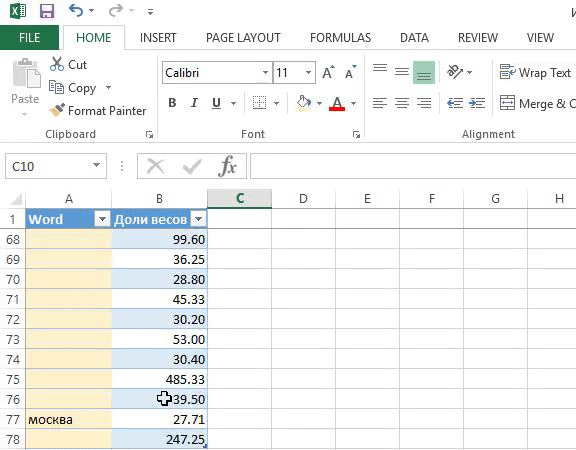
3. Удаляем пустые ячейки и считаем кол-во упоминаний каждого слова.
Шаг 3. Выделяем леммы и дорабатываем справочник со словами
Лист «Слова — Леммы», таблица «Word»
- Копируем полученный на прошлом шаге список слов «как есть».
- Обрабатываем через mystem → получаем леммы для каждого слова.
- Считаем кол-во упоминаний каждой леммы.
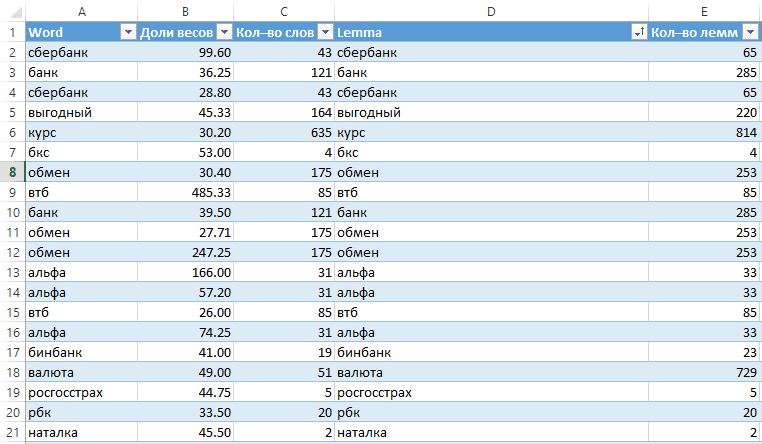
Справочник слов
Шаг 4. Формируем таблицу-справочник с леммами
Лист «Леммы», таблица «Lemmas»
- Копируем полученный список лемм на новый лист и удаляем дубли.
- Из справочника со словами подтягиваем VLOOKUP-ом кол-во упоминаний каждой леммы.
- Считаем кол-во символов в лемме.
- Вычисляем «вес» леммы:Вес Леммы= [Сумма долей весов слов, входящих в Лемму] * [Кол-во упоминаний Леммы].Формула:=(SUMIF (Words[Lemma],[@Лемма], Words[Доли весов]))*[@[Кол-во упоминаний]].
- Сортируем леммы по столбцу «вес» — от большего к меньшему.
- Проставляем «Статус» для лемм — минимальный для старшей леммы (лучше начать с 1 000), дальше +1 к следующему статусу:
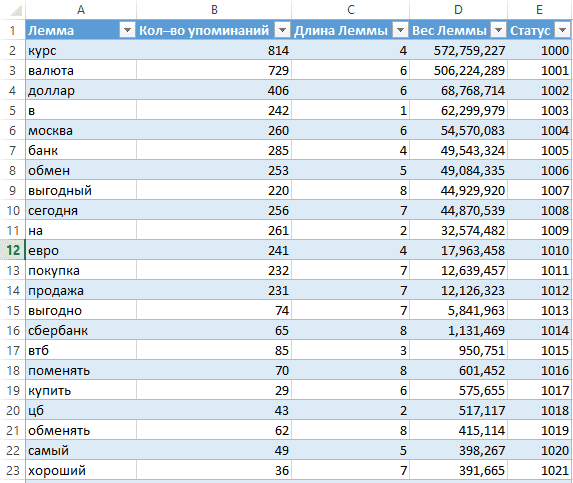
Справочник лемм
Шаг 5. Делаем первичную кластеризацию
Лист «Кластеризация», таблица «Main»
Для каждого слова в столбцах W1-W7 подтягиваем VLOOKP-ом значения «Статус» → записываем их столбцы L1-L7:
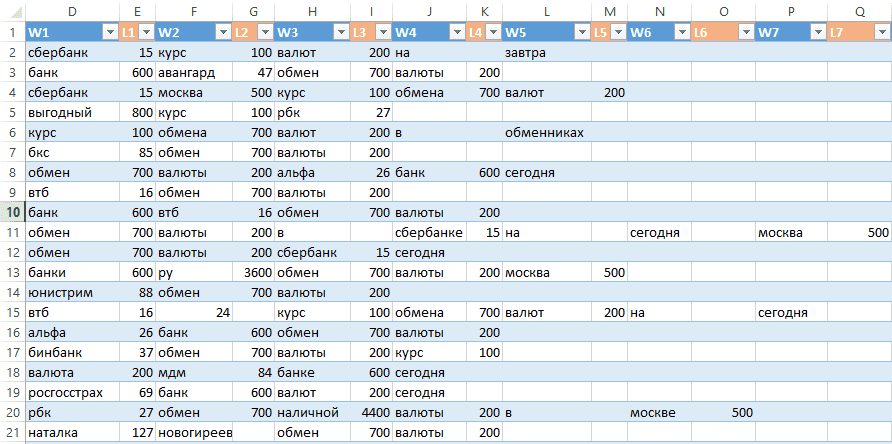
«Статусы» слов
Итак, что мы сделали. Разбили запросы по словам. Для каждого слова выделили лемму — можем объединить запросы по общим словам. Для каждой леммы посчитали вес. Остаётся выстроить слова в запросе в порядке важности. Тогда при сортировке по алфавиту запросы сами объединятся в группы объявлений.
Выстраиваем слова в порядке важности функцией SMALL. В диапазоне статусов L1 – L7 ищем самый маленький статус — это самое важное слово во фразе. Затем, ищем второй самый маленький статус — это второе по важности слово во фразе. И так еще пять раз — проверяем оставшиеся столбцы L3 – L7.
Получаем последовательность статусов. Например, 37 → 100 → 200 → 700. Для каждого статуса подтягиваем VLOOKP-ом соответствующую Лемму из справочника Лемм. Соединяем Леммы CONCATENATE-ом и получаем нормализованное значение фразы. Я использую его как название группы объявлений.
Сортируем по алфавиту:
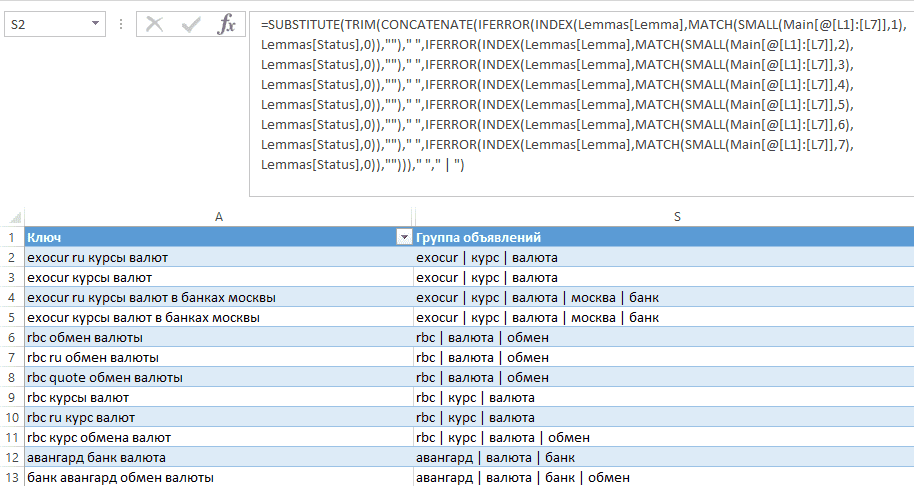
Результаты работы Кластеризатора
Полная рабочая формула в файле-примере.
Шаг 6. Укрупняем полученные группы
Игнорируя окончания и порядок слов, мы объединили запросы с одинаковым набором слов. Количество групп стремится к количеству слов — это 100 % точность инструмента. Можно использовать, если вы предпочитаете работать с запросами в точном соответствии.
Чтобы укрупнить группы, нужно уменьшить точность — снизить количество лемм, которые составляют «нормализованную форму».
Что можно удалить:
- одинокие буквы, цифры, предлоги, доменные зоны. Леммы длиной 1–3 символа;
- редкие леммы — кол-во упоминаний меньше среднего по списку;
- леммы с малым весом — недостаточно «важные»;
- в редких случаях — топонимы.
Важно: лемму не удаляем, только её «Статус» — этого достаточно, чтобы лемма не попала в «нормализованную форму»:
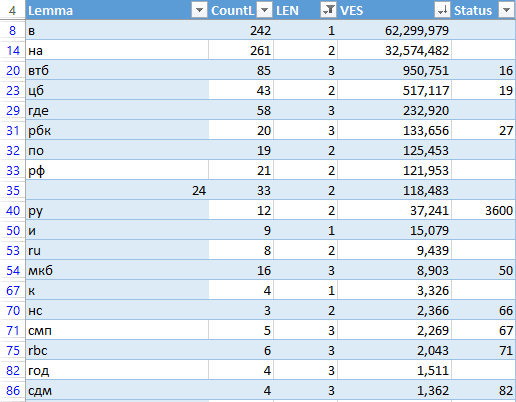
Процесс укрупнения групп объявлений
В основной таблице ничего править не надо — результат обновится самостоятельно.
До какой степени укрупнять: я стремлюсь к среднему показателю 2–3 запроса в одной группе объявлений и слежу за максимальным количеством фраз (помним про ограничения систем контекстной рекламы).
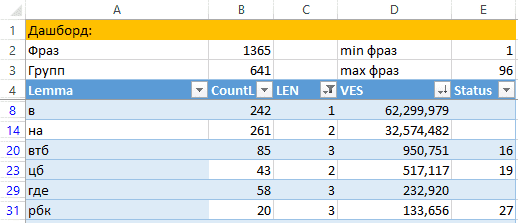
Дашборд для укрупнения в справочнике Лемм
Резюме
Полученный список групп удобно кросс-минусовать и двигать между кампаниями. Название группы поможет писать объявления — вы сами определяете важные слова в названии группы.
Ещё раз алгоритм: собираем СЯ → собираем частотность → разбиваем запросы по словам и вычисляем доли весов → формируем таблицу-справочник с весами слов → выделяем леммы для слов → вычисляем «вес» леммы → формируем таблицу-справочник с леммами → делаем первичную кластеризацию → укрупняем полученные группы.
Отзывы джедаев о кластеризаторе
«Я помогал Роме с созданием инструмента на ранних этапах. Всем рекомендую попробовать кластеризатор для ядра от 2000 ключевых слов → сэкономит время.
Инструмент можно улучшить и превратить в автоматический сервис. Также можно дорабатывать формулы определения веса лемм. Но и в текущем виде он поможет специалистам по контексту, которые работают с большой семантикой»
Илья Ерошкин
Старший джедай
«Методику пробовал, но не использую в работе, потому что нечасто собираю контекст в больших объемах.
Хорошо подойдет для работы с большой семантикой, особенно в свете последних нововведений яндекса по низкочастотным запросам. Группировки помогут сэкономить много времени при подготовке ключевых фраз.
Методика на первый взгляд кажется сложной и громоздкой, но если разобраться, то процесс становится понятным и удобным»
Михаил Стерликов
Старший джедай
«Кластеризация от Ромы просто находка! Методом пользуюсь каждый раз когда работаю с семантикой — собираю или корректирую кампании.
Больше всего мне нравятся три вещи:
- я регулирую какие фразы попадут в группу. Если вес фразы небольшой, то объединяю с похожими. Не придерживаюсь принципа «один ключ — одна группа», иначе управлять кампанией сложно;
- понимаю механику и вижу какие фразы должны быть в заголовке. Конечно, важно делать полное вхождение ключевого слова. Часто оно не вмещается полностью и я строю заголовок из фраз с бо́льшим весом;
- это Excel, который всем знаком. Не нужно устанавливать дополнительные программы и платить за сервис. Если разобраться в формулах, то уже немного прокачаешься.
Из минусов: все формулы я копирую из готового шаблона и переключаться между окнами одной программы неудобно. Я бы хотела иметь формулы под рукой, а может сделать в будущем какой-нибудь шаблон, чтобы сократить количество копирований. Ещё хотелось бы сократить время группировки, но пока не нашла способ.
В целом, способ мне нравится тем, что механика простая и понятная, её легко внедрить и потом управлять кампаниями»
Александра Мурашко
Джедай
«С помощью кластеризатора сильно удобнее и быстрее сгруппировать фразы и потом писать объявления для них. Из недостатков — первый раз кажется, что это сложновато. Но когда попробуешь, то всё довольно понятно. Но эту штуку лучше автоматизировать»
Егор Холов
Старший джедай
Что дальше
Если у вас СЯ от 2–3 тысяч ключевых слов, используйте этот алгоритм. Прогоните алгоритм 2–3 раза, чтобы «впитать».
Если у вас список из 200–300 запросов, переберите руками — так быстрее.
Если хотите готовое решение — попросите программистов написать скрипт.
Я постоянно дорабатываю кластеризатор. В следующих итерациях хочу проработать кросс-минусовку групп, добавить справочники минус-слов и максимально автоматизировать кластеризатор на Power Query. Следите за обновлениями!
Будут вопросы — пишите: igoshinrmn@it-agency.ru или Facebook.
Таблица-пример
Записал и отредактировал Виталий Семыкин

Контекстная реклама
Подобрали для вас
Контекстная реклама
 Инструмент для поиска битых ссылок в рекламных объявлениях Яндекс.Директа
Инструмент для поиска битых ссылок в рекламных объявлениях Яндекс.ДиректаКонтекстная реклама
Эльдар Забитов — Инструмент для поиска битых ссылок в рекламных объявлениях Яндекс.ДиректаКонтекстная реклама
 Получили доступ к рекламе в ChatGPT и протестировали кабинет. Вот что узнали про форматы, требования и возможности
Получили доступ к рекламе в ChatGPT и протестировали кабинет. Вот что узнали про форматы, требования и возможностиЕщё по теме «контекстная реклама»
Контекстная реклама
 Как повысить эффективность продвижения, сочетая retention-маркетинг и рекламу
Как повысить эффективность продвижения, сочетая retention-маркетинг и рекламуКонтекстная реклама
Видеозапись вебинара «Как оптимизировать контекстную рекламу в кризис»Контекстная реклама
Sourcebuster JSКонтекстная реклама
Эльдар Забитов — Инструмент для выгрузки отчётов напрямую из Яндекс.ДиректаКонтекстная реклама
 «Поговорили, как будто агентство нужно звать всегда, но это не так». Разбираем кейсы, когда от него будет польза, а когда лучше обойтись своими силами
«Поговорили, как будто агентство нужно звать всегда, но это не так». Разбираем кейсы, когда от него будет польза, а когда лучше обойтись своими силамиКонтекстная реклама
Рекламная кампания теряет эффективность: что проверитьСтатьи из Академии
два раза в месяц
Даю согласие на обработку моих данных в соответствии с политикой обработки


Обсудим задачу
Мы свяжемся с вами в течение двух часов, чтобы задать вопросы и обсудить, какую пользу можем принести

Александр Кульгинский
управляющий партнёр