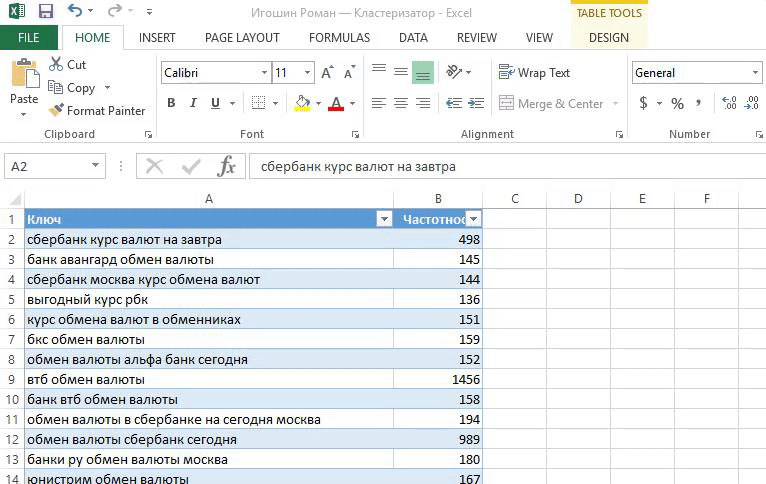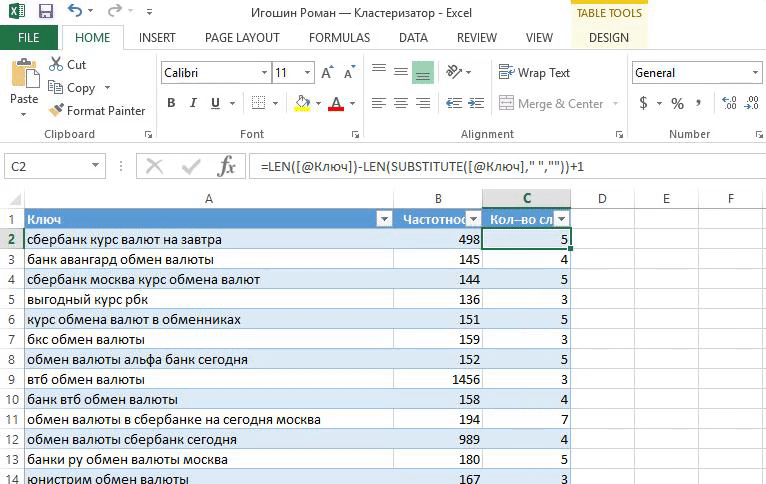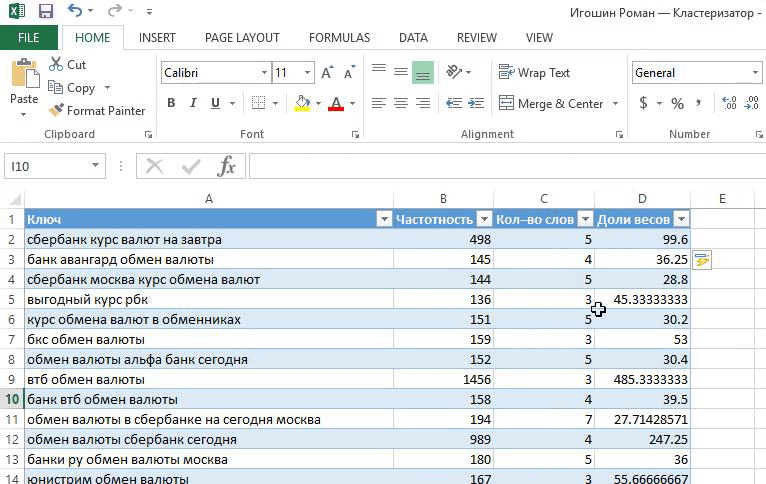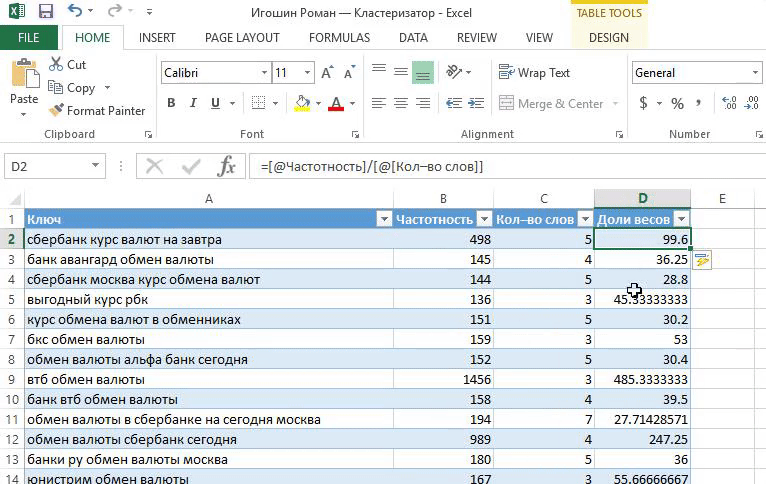
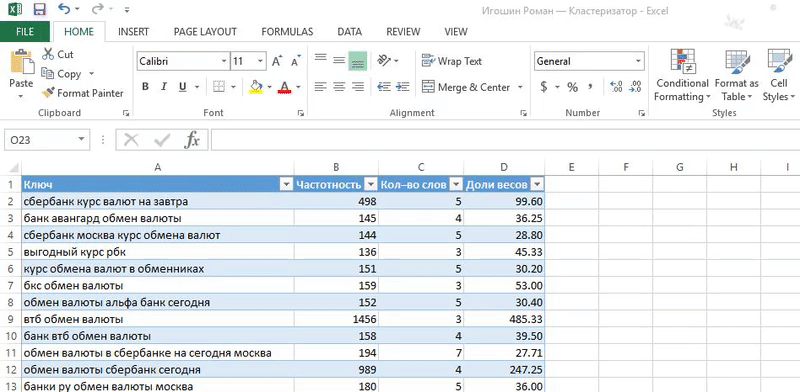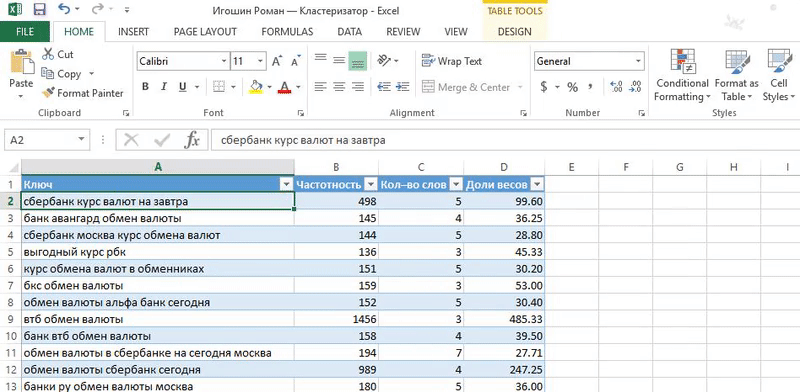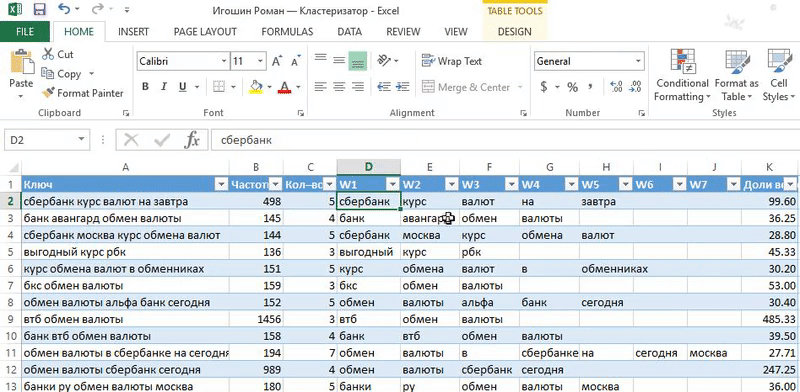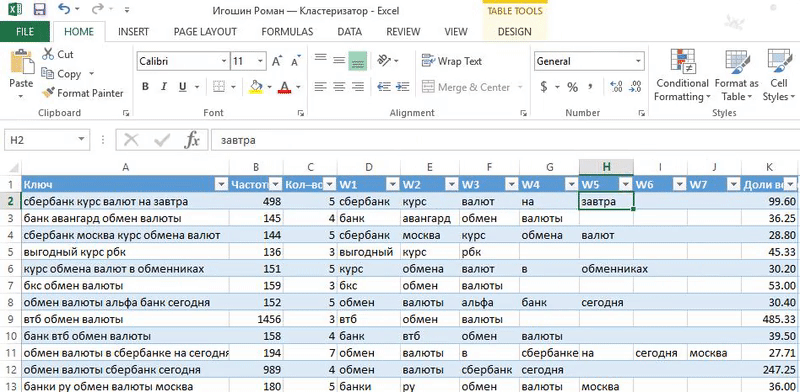
«Кластеризация от Ромы просто находка! Методом пользуюсь каждый раз когда работаю с семантикой — собираю или корректирую кампании.
Больше всего мне нравятся три вещи:
-
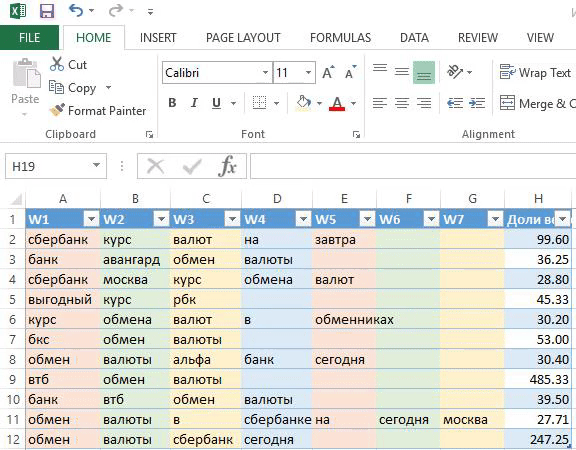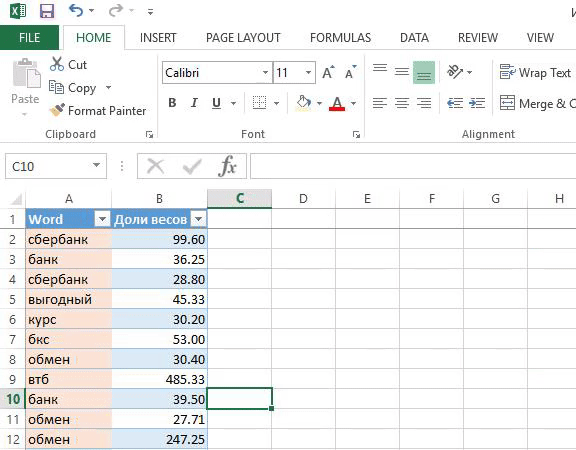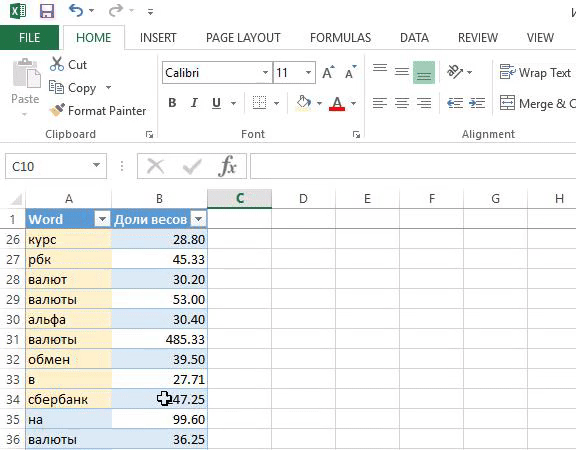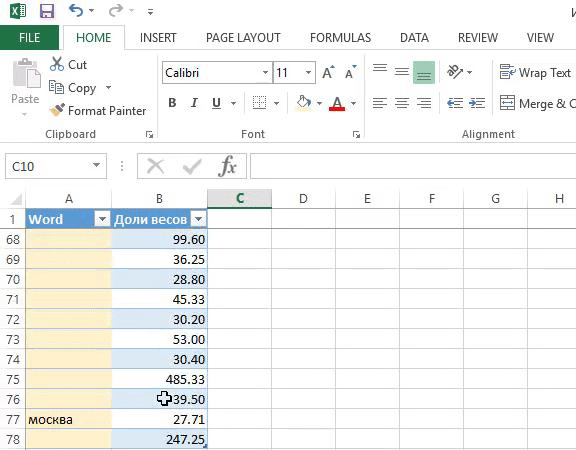
я регулирую какие фразы попадут в группу. Если вес фразы небольшой, то объединяю с похожими. Не придерживаюсь принципа «один ключ — одна группа», иначе управлять кампанией сложно;
-
понимаю механику и вижу какие фразы должны быть в заголовке. Конечно, важно делать полное вхождение ключевого слова. Часто оно не вмещается полностью и я строю заголовок из фраз с бо́льшим весом;
-
это Excel, который всем знаком. Не нужно устанавливать дополнительные программы и платить за сервис. Если разобраться в формулах, то уже немного прокачаешься.
Из минусов: все формулы я копирую из готового шаблона и переключаться между окнами одной программы неудобно. Я бы хотела иметь формулы под рукой, а может сделать в будущем какой-нибудь шаблон, чтобы сократить количество копирований. Ещё хотелось бы сократить время группировки, но пока не нашла способ.
В целом, способ мне нравится тем, что механика простая и понятная, её легко внедрить и потом управлять кампаниями»